
{kind=link}
Application performance monitoring is a technology-driven process to ensure business applications perform as expected through real-time performance tracking and trend analysis. In APM initiatives, IT professionals use monitoring tools and telemetry data to help detect, identify and troubleshoot performance issues in applications.
APM falls under the more general practice of application performance management. While the two might sound like the same process, they have different scopes and goals. Application performance monitoring focuses narrowly on tracking and improving the performance of individual applications to address problems as they arise. Application performance management encompasses that but also looks more broadly at optimizing application performance levels and health over time. In essence, performance monitoring is a key part of performance management.
An effective application performance monitoring program should track the processing of transactions and other types of user interactions, as well as the user experience (UX) and the status of application and IT infrastructure components. APM tools provide developers, application analysts, system administrators and IT operations workers with the data they need to resolve problems that affect an application’s performance. The data collected by the tools includes various performance metrics that teams can use to analyze the root cause of performance problems and take corrective actions.
This comprehensive guide to application performance monitoring further explains what APM is, why it’s important and how it works. It also covers the benefits of effective APM efforts, challenges to be aware of, best practices for APM practitioners, available APM tools and more. Throughout the guide, hyperlinks point to related articles that provide more information and expert advice.
What is the purpose of APM?
APM proactively monitors the performance and behavior of applications and the systems they run on. The goal is to quickly find and fix performance issues — ideally, before an application’s users are affected to any noticeable degree. APM also helps development teams reduce the mean time to repair software defects that cause application errors or failures.
Without APM tools and processes, identifying and correcting application performance problems would be much more daunting. In modern IT environments, applications often involve numerous microservices — dozens or more in some cases — running across distributed systems. Each service handles a portion of the processing workload. The use of containers, different APIs and various cloud services, including third-party ones, further increases application complexity.
It’s an arduous task to manually pinpoint the cause of slowdowns or errors in such applications — for example, by reading through an application log. APM streamlines things by collecting various types of performance data for easy access by developers, application analysts and other IT pros. In addition to monitoring real-time performance status, it supports analysis of retained historical data to identify performance trends or hidden factors that are contributing to issues.
Why is APM important?
Ensuring that applications work well is a must for any organization. Uninterrupted application availability and efficient performance are essential to keep business processes running smoothly. Successful APM efforts that help do so lead to positive business outcomes and enable companies to avoid potential negative ones. For example, strong application performance prevents business disruptions, enhances customer satisfaction and improves financial performance.
Even with APM, some performance issues are inevitable, especially in complex applications with large numbers of users. But APM’s rapid detection and diagnosis capabilities help minimize the duration of performance glitches or, in the worst cases, application downtime. This reduces frustration levels for internal users and customers alike. It also limits damage to a company’s brand and reputation.
In addition, troubleshooting and remediating applications cost money and take up valuable developer time. APM can bring direct savings in both of those areas, enabling organizations to focus more of their development budget and resources on new applications or added functionality.
What are the components of APM?
Not surprisingly, monitoring functionality is the core element of the APM process. But various forms of monitoring can be done: APM tools gather data from almost anything that plays a role in an application’s performance. After being collected, the various metrics are commonly displayed in data visualizations and dashboards for use in performance tracking and analysis.
In the early 2000s, consulting firm Gartner outlined five functional dimensions of application performance monitoring. Listed below, they’re still widely cited as a conceptual framework for APM — even though Gartner later revised its model.
1. UX monitoring
This involves gathering data to understand how well an application is performing for end users and gauge potential performance problems. For example, APM might monitor a website’s response times and flag ones that exceed a predefined threshold to alert developers about possible latency or application response issues. These activities can be done through end-user experience monitoring (EUEM) or the broader practice of digital experience monitoring (DEM), which measures all of a user’s digital interactions across various channels, processes and devices.
As part of either approach, these are the two principal ways to track UX:
- Real user monitoring. RUM tracks user sessions in live applications to provide a real-world view of performance and availability levels. Development and IT operations teams can see exactly what’s happening in applications as employees or customers use them. RUM is described as a passive monitoring method due to its reliance on data generated by application users.
- Synthetic monitoring. Described as an active monitoring method, synthetic monitoring simulates user sessions to detect and identify performance problems. It can be done during development and testing or in live applications to check for issues proactively. It’s also used to monitor service-level agreements (SLAs) associated with applications.
2. Application runtime architecture discovery and modeling
This aspect models the various hardware and software components that execute an application and the paths they use to communicate with each other. When a performance problem is detected, IT teams can analyze the application architecture to identify the issue’s possible scope and help guide more granular monitoring work. Pattern recognition can also be used to anticipate the potential for future problems and plan for preemptive upgrades, such as more CPU or storage resources.
3. User-defined transaction profiling
Also referred to as business transaction monitoring, this focuses on examining specific user interactions with an application to understand the conditions that led to a performance problem. Doing so helps organizations trace discrete performance events and pinpoint where they’re occurring as user requests move across an application’s various components, such as different microservices. It also shows whether performance efficiency is optimized at each step in the process.
4. Deep-dive component monitoring
This involves tracking all the components in an application architecture to evaluate what’s causing identified performance problems. That includes in-depth monitoring and analysis of the application components and supporting IT infrastructure, such as application servers and other middleware, databases and network flows. Component monitoring provides a deeper understanding of an application’s various elements and pathways.
5. Performance analytics and reporting
This involves translating the performance data gathered from the above processes into actionable information that can be used to do the following:
- Identify and resolve performance issues and their root causes.
- Define a performance baseline using historical and current data to set an expectation for normal application performance.
- Identify potential areas of improvement by comparing application and infrastructure changes to changes in performance.
- Predict potential future issues and devise plans to avoid them.
APM tools commonly provide interactive data exploration and analytics capabilities. Increasingly, they support the use of AI and machine learning to automate the analysis of performance data and do advanced analytics, such as data mining or anomaly detection. Both prebuilt and customized dashboards can be used to visualize, share and report on performance data, identified issues and APM initiatives.
How does APM work?
Application performance monitoring tools track how applications are performing and whether they’re behaving as expected. If an application isn’t functioning properly, performance data is analyzed to identify the source of the issue and perform root cause analysis. After the situation is understood, actions are taken to resolve the issue. In addition, the application environment can be corrected as needed to avoid recurrences or similar problems in other application components.
At the application level, APM tools measure average response times, error rates, uptime and other performance metrics. They also monitor code execution to detect possible bottlenecks during application functions, such as processing steps, database queries or API calls. At the infrastructure level, the tools look for sudden spikes in the use of system resources that might indicate performance problems. That’s all in addition to the in-depth component monitoring done after issues are identified.
Monitoring can be done with or without the help of software agents. In agent-based monitoring, agents are installed in applications to collect performance data. What they collect is driven by commands and scripts in code that’s added to the application — a process called instrumentation. Agentless monitoring, on the other hand, uses standard communication protocols to collect network traffic data.
Agents typically can gather more detailed performance data on a wider range of metrics based on how they’re instrumented, but they add processing and management overhead. Conversely, agentless monitoring requires fewer resources and can be deployed and scaled more easily, but its data collection capabilities are generally more limited. As a result, the choice between them depends on an organization’s application environment, performance monitoring needs and budget.
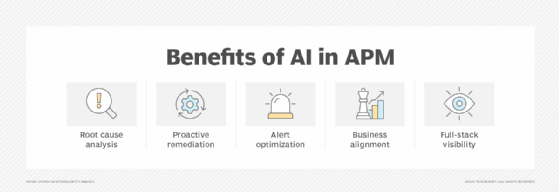
AI and machine learning tools can also help in the APM process beyond analyzing performance data. For example, AI algorithms built into APM platforms can map interdependencies between the different components of complex applications and automatically detect and remediate performance issues. AI can also automate alerting, notification and issue escalation procedures.
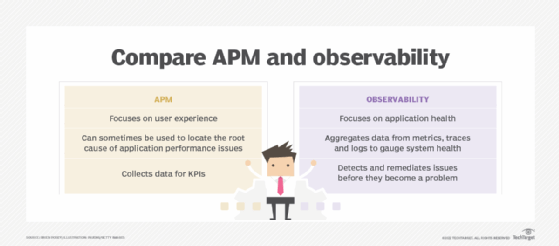
How is APM different from observability?
Application performance monitoring and observability, which emerged more recently as an IT process, are sometimes seen as the same thing. On the surface, they share the same purpose: to measure performance and identify potential problems in applications and underlying systems. But they diverge in scope, as observability provides a more comprehensive view of application health and behavior.
Fundamentally, the difference between observability and APM lies in the amount of data collected and how it’s processed and analyzed. Observability aims to gauge the internal state of applications and systems by collecting a broader set of telemetry data and supporting more sophisticated exploratory analytics. While traditional APM mainly focuses on performance metrics, observability also incorporates the following data types:
- Traces. A trace measures the duration of each portion of the processing work as a user request moves between different services and functions in a distributed system. That data can indicate the location of an application error or a performance bottleneck in the system.
- Logs. Automatically created by an application or OS, log files hold basic details about user actions, error messages and other events in the app. Logs can help developers diagnose performance issues by providing information on everything that happens in an application.
Metrics, traces and logs are often described as the three pillars of observability. In that sense, APM can be viewed as an element of observability. Gartner, for one, has adopted that view; its long-running annual Magic Quadrant report on APM tools was expanded to cover APM and observability ones in 2022 and then refocused in 2024 on observability platforms, most of them with APM capabilities included.
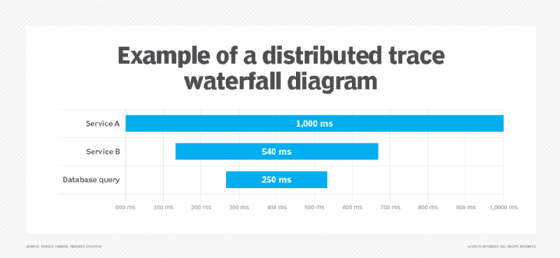
How is APM different from distributed tracing?
Distributed tracing is the process of capturing traces in applications. From a technical perspective, APM and tracing are separate processes. While APM provides an overview of application performance, distributed tracing gives developers a detailed view of how an application performs on specific user requests that pass through various services and other components of a distributed system. Traces are broken down into spans, which represent the individual units of work done by different services. Treelike or waterfall diagrams are commonly used to visualize traces, with each span appearing in a separate bar.
When developers troubleshoot a performance issue, the average processing time recorded for each span in a trace can be used to identify which service is slowing things down or causing application errors. However, APM and distributed tracing are often used together, in keeping with metrics and traces being two of observability’s pillars. While distributed tracing tools initially were a standalone technology category, many APM platforms now provide tracing capabilities.
There’s a similar dynamic between distributed tracing and logging. Text-based application logs provide a chronological list of events with timestamps, status information, error codes and other data. Log files offer clues for debugging performance issues but don’t readily show the chain of processing steps that traces do. As a result, tracing and logging complement one another and can both be used alongside APM.
Key APM metrics
Many metrics can be used to measure the performance and status of an application. The following are some common application performance metrics tracked as part of APM initiatives:
- Response time. This is how long an application takes overall to process user requests or queries.
- Latency. A part of response time, latency tracks the delay between user requests being initiated and an application starting to process them.
- Error rate. This measures the percentage of user requests that result in errors vs. the total number of requests being processed.
- Application availability and uptime. Rates measuring how often an application is running and available to users are often used to track SLA compliance in addition to their APM use.
- Throughput. This tracks the total number of requests or transactions an application processes in a defined amount of time — per second, for example.
- Request rate. This measures the amount of traffic an application receives to identify significant increases or decreases in usage that could affect performance requirements.
- Apdex score. Application Performance Index, or Apdex for short, is a standard for calculating a perceived user satisfaction score by comparing response times to a predefined threshold.
- CPU usage. This measures the percentage of CPU resources an application is consuming to detect abnormally high utilization levels that could slow performance.
- Memory usage. Similarly, high levels of memory usage can affect application performance, making this a metric that development and IT operations teams typically track.
What are the benefits and challenges of APM?
Effective APM strategies offer various business benefits to organizations, including the following:
- Reduced time to recovery. By accelerating efforts to detect and address performance issues, APM shortens recovery times from application outages and other incidents.
- More rapid defect diagnosis. APM helps developers zero in on what’s causing performance problems, eliminating guesswork and trial-and-error approaches to diagnosing them.
- Increased software engineering productivity. APM can identify performance issues during the development process, enabling teams to fix defects upfront and avoid rework after applications go live.
- Improved application stability and uptime. Successful APM initiatives result in more stable applications with less downtime by both fixing issues faster and avoiding them in the first place.
- Fewer business disruptions. In turn, better stability and uptime through APM minimize disruptions to business operations from application performance issues.
- Lower costs and more efficient use of IT resources. APM insights can lower development costs and spending on upgrades to an application’s system infrastructure to boost performance.
- Better end-user experience. APM helps development and IT operations teams optimize application performance for end users, resulting in an improved UX.
- Higher customer satisfaction levels. A well-managed APM process leads to more satisfied customers, whether they’re actual customers or internal users.
APM provides additional technical benefits, such as streamlined SLA compliance tracking and the ability to troubleshoot performance issues in a controlled environment. It also supports application lifecycle management programs that provide a structured approach to the software development process, from defining requirements for an application to deployment and ongoing maintenance.
However, APM also poses challenges for organizations. As mentioned previously, modern application architectures can be notoriously complex. They often involve numerous services in distributed systems across multiple locations, including the cloud and on-premises data centers. Cloud-native applications and the increasing use of AI in business applications add to the complexity. This makes it difficult to monitor application performance effectively without solid planning and oversight of APM programs.
The following are some specific challenges and potential missteps in the APM process:
- Using the wrong metrics. APM isn’t automatic; it’s up to the organization to choose the most meaningful performance metrics for the application being monitored.
- Not using the collected metrics. Metrics are useless if they aren’t actively used to track application performance and help identify issues.
- Inadequate technical skills. The complexity of modern applications requires APM work to be done by IT pros with the appropriate skills for the job.
- Unclear goals. Understanding performance requirements and the goals of an APM initiative is a must. Performance monitoring for its own sake has no value to the business or end users.

What can be monitored with APM?
APM initiatives break down traditional monitoring silos for seamless application tracking. That includes the following:
- Front-end monitoring gauges an application’s performance from the user’s standpoint.
- Back-end monitoring tracks the various services used by the application and their dependencies.
- Infrastructure monitoring assesses whether applications are running on a well-configured and functional system infrastructure.
Developers can prioritize applications for monitoring based on how critical they are to the business. In addition, teams can create rules and select monitoring parameters to trigger alerts when a problem is detected or an application’s performance deviates from an established baseline. In many APM tools, alerting rules can be dynamic, with conditions that vary based on application workloads or other factors.
The cloud introduces a host of additional dependencies into application performance, even when applications aren’t based in the cloud themselves. Cloud application performance monitoring is a form of APM that tracks apps running in the cloud, including ones in private cloud or hybrid cloud deployments. For example, an APM platform will monitor for communication problems between a cloud application and other cloud services the application connects to. It also looks for latency issues between the application and end users.
Other types of monitoring that can be done include mobile application monitoring to track and optimize mobile app performance; microservices monitoring to provide insight into performance in microservices environments; and website performance monitoring that focuses on web applications.
Also, automated application or network load balancing that spreads traffic across different servers can fool IT teams into thinking that everything is working properly because the combined performance of the servers appears to be fine. In reality, the automated balancing could be masking issues that leave some servers carrying more of the load than others. APM can help avoid this issue by simultaneously tracking performance at all the servers to identify where problems are occurring.
Application performance monitoring best practices
Because APM can be complicated and demanding, it requires careful thought, comprehensive planning and regular review. The following best practices for APM initiatives can help businesses get the most from their investments in the process:
- Set clear application performance goals. Not establishing minimum acceptable performance levels for different applications makes it hard for development and IT operations teams to know where to focus their efforts when issues arise in multiple apps.
- Collect granular performance data. Detailed metrics enable teams to address performance issues more effectively, especially in complex applications.
- Don’t collect irrelevant data. On the other hand, collecting unneeded performance data adds more complexity and cost to APM processes.
- Configure dynamic alerting thresholds. Teams should take advantage of the dynamic alerting capabilities in APM tools to avoid unnecessary alerts about things that aren’t really problems.
- Establish a response plan for performance issues. Teams should also be prepared to respond when performance problems occur, with clear instructions on who does what.
- Create effective data retention policies. Performance data is often retained to analyze performance trends, but keeping it longer than needed wastes money on storage.
- Choose cost-effective storage technology. A storage infrastructure that balances cost considerations with I/O performance needs can also reduce APM spending.
- Anonymize and secure APM data. Any performance data with security or compliance implications should be secured properly and anonymized if necessary.
- Consider automated issue remediation. Using AI and automation capabilities to fix performance issues can reduce developer workloads and address problems before they affect users.

APM tools and vendors
Organizations can choose from a wide range of APM tools. Some are dedicated to APM tasks, while others have been rebranded as more expansive observability platforms. In other cases, APM functionality has been built into enterprise IT monitoring tools with broader features.
The following is an alphabetical list of some popular tools compiled by Informa TechTarget editors based on research of the available offerings and Gartner’s observability platforms Magic Quadrant report. Vendors are listed parenthetically if they aren’t mentioned in product names:
- Amazon CloudWatch (AWS).
- Azure Monitor Application Insights (Microsoft).
- BMC Stackify.
- Datadog.
- DX Application Performance Management (Broadcom).
- Dynatrace.
- EG Enterprise.
- Elastic Observability.
- Google Cloud Observability.
- Grafana Cloud.
- Honeycomb.
- IBM Instana Observability.
- LM APM (LogicMonitor).
- Logz.io.
- Lumigo.
- ManageEngine Applications Manager.
- New Relic.
- Oracle Cloud Observability and Management Platform.
- Raygun Application Performance Monitoring.
- Riverbed APM.
- Scout Monitoring.
- Sentry.
- ServiceNow Cloud Observability.
- SolarWinds Observability SaaS.
- Splunk AppDynamics.
- Splunk Observability Cloud.
- Sumo Logic Application Observability.
Open source APM tools are also available; Apache SkyWalking, Scouter, SigNoz and Uptrace are some notable examples. In addition, many commercial and open source tools alike support OpenTelemetry, an open source observability framework. It provides APIs, SDKs and tools to simplify the process of collecting metrics, traces and logs and prevent vendor lock-in on tools.
Based on their needs, organizations can instead choose narrower deployments of end-user experience monitoring tools that focus on RUM and synthetic monitoring. Such tools — alternatively branded as digital experience monitoring ones in some cases — are separate product modules in many APM and observability platforms. They’re also offered by vendors that specialize in EUEM and DEM.
Key features of APM tools
Given all the potential choices between tools, organizations should invest considerable time and effort in feature evaluation as part of the technology selection process to be sure they get the required monitoring capabilities. Individual tools have strengths in different aspects of APM.
In general, though, an APM tool should be able to efficiently collect performance data at scale, monitor the full infrastructure stack that supports an application, streamline analysis of performance issues and identify connections between application performance and business outcomes.
The following are some specific features that APM tools typically provide:
- Support for collecting various types of performance metrics.
- The ability to create custom metrics.
- RUM, including both client- and server-side metrics.
- Session replay to recreate and view user sessions.
- Synthetic monitoring.
- Agent-based and agentless monitoring.
- Distributed tracing.
- Application logging and log management.
- Application dependency mapping.
- Error reporting for application defects and bugs.
- Root cause analysis of performance issues.
- Analytics driven by AI and machine learning.
- Prebuilt and customizable dashboards.
- Alerting, notification and other automated response functions.
- Load testing to evaluate application scalability.
- Integrations with third-party services and applications.
Integrating APM into your business
Tools alone don’t make a successful APM initiative. Business and technology leaders should consider the following questions before launching an APM program:
- Are there applications or services that would benefit from performance monitoring? These typically are mission-critical workloads where disruptions would affect business operations.
- What performance data is most relevant to those applications or services? Find out what metrics should be collected about the application workloads that will be monitored. An APM tool can likely capture far more data than needed, so be selective about what’s really needed.
- What’s required for analytics, alerting and reporting? Discuss how metrics and data should be processed, when alerts would be called for, what should be included in reports and the kinds of insights required from analytics.
- Who owns APM? Consider the stakeholders involved in an APM deployment, from application owners to IT administrators. Decide who has responsibility for the APM initiative.
- How should an APM tool be used? Plan out a tool’s role in the APM process, from monitoring and data collection to triggering alerts or implementing automated responses.
- What APM tools meet these criteria? Assess prospective APM tools against the requirements and create a short list of potential candidates to evaluate.
- Can the APM tools being evaluated work within the application environment? Use proof-of-concept testing to validate that tools meet the requirements and are suited to the environment.
- Can the APM plans be easily changed? Address how easily prospective APM processes and tools can be adapted to new business needs — for example, to create custom metrics or accommodate new use cases.
With these questions answered, a business can decide whether to move forward with an APM deployment. It’s often best to start small with a single application, develop expertise and then systematically expand the APM practices.
Editor’s note: This article was updated in April 2025 for timeliness and to add new information.
Craig Stedman is an industry editor at Informa TechTarget who creates in-depth packages of content on analytics, data management and other technology areas.
Stephen J. Bigelow, senior technology editor at Informa TechTarget, has more than 30 years of technical writing experience in the PC and technology industry.
This was last updated in April 2025