
{kind=link}
This post is co-written with Eliuth Triana Isaza, Abhishek Sawarkar, and Abdullahi Olaoye from NVIDIA.
Today, we are excited to announce that the Llama 3.3 Nemotron Super 49B V1 and Llama 3.1 Nemotron Nano 8B V1 are available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can now deploy NVIDIA’s newest reasoning models to build, experiment, and responsibly scale your generative AI ideas on AWS.
In this post, we demonstrate how to get started with these models on Amazon Bedrock Marketplace and SageMaker JumpStart.
About NVIDIA NIMs on AWS
NVIDIA NIM inference microservices integrate closely with AWS managed services such as Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon SageMaker AI, to enable the deployment of generative AI models at scale. As part of NVIDIA AI Enterprise, available in the AWS Marketplace, NVIDIA NIM is a set of easy-to-use microservices designed to accelerate the deployment of generative AI. These prebuilt containers support a broad spectrum of generative AI models from open source community models to NVIDIA AI Foundation and custom models. NIM microservices are deployed with a single command for easy integration into generative AI applications using industry-standard APIs and just a few lines of code, or with a few actions in the SageMaker JumpStart console. Engineered to facilitate seamless generative AI inferencing at scale, NIM ensures generative AI applications can be deployed anywhere.
Overview of NVIDIA Nemotron models
In this section, we provide an overview of the NVIDIA Nemotron Super and Nano NIM microservices discussed in this post.
Llama 3.3 Nemotron Super 49B V1
Llama-3.3-Nemotron-Super-49B-v1 is an LLM which is a derivative of Meta Llama-3.3-70B-Instruct (the reference model). It is a reasoning model that is post-trained for reasoning, human chat preferences, and task executions, such as Retrieval-Augmented Generation (RAG) and tool calling. The model supports a context length of 128K tokens. Using a novel Neural Architecture Search (NAS) approach, we greatly reduced the model’s memory footprint and increased efficiency to support larger workloads and for the model to fit onto a single Hopper GPU (P5 instances) at high workloads (H200).
Llama 3.1 Nemotron Nano 8B V1
Llama-3.1-Nemotron-Nano-8B-v1 is an LLM which is a derivative of Meta Llama-3.1-8B-Instruct (the reference model). It is a reasoning model that is post trained for reasoning, human chat preferences, and task execution, such as RAG and tool calling. The model supports a context length of 128K tokens. It is created from Llama 3.1 8B Instruct and offers improvements in model accuracy. The model fits on a single H100 or A100 GPU (P5 or P4 instances) and can be used locally.
About Amazon Bedrock Marketplace
Amazon Bedrock Marketplace plays a pivotal role in democratizing access to advanced AI capabilities through several key advantages:
- Comprehensive model selection – Amazon Bedrock Marketplace offers an exceptional range of models, from proprietary to publicly available options, allowing organizations to find the perfect fit for their specific use cases.
- Unified and secure experience – By providing a single access point for all models through the Amazon Bedrock APIs, Bedrock Marketplace significantly simplifies the integration process. Organizations can use these models securely, and for models that are compatible with the Amazon Bedrock Converse API, you can use the robust toolkit of Amazon Bedrock, including Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Flows.
- Scalable infrastructure – Amazon Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
Deploy NVIDIA Llama Nemotron models in Amazon Bedrock Marketplace
Amazon Bedrock Marketplace gives you access to over 100 popular, emerging, and specialized foundation models (FMs) through Amazon Bedrock. To access the Nemotron reasoning models in Amazon Bedrock, complete the following steps:
- On the Amazon Bedrock console, in the navigation pane under Foundation models, choose Model catalog.
You can also use theInvokeModelAPI to invoke the model. TheInvokeModelAPI doesn’t support Converse APIs and other Amazon Bedrock tooling. - On the Model catalog page, filter for NVIDIA as a provider and choose the Llama 3.3 Nemotron Super 49B V1 model.
The Model detail page provides essential information about the model’s capabilities, pricing structure, and implementation guidelines. You can find detailed usage instructions, including sample API calls and code snippets for integration.
- To begin using the Llama 3.3 Nemotron Super 49B V1 model, choose Subscribe to subscribe to the marketplace offer.
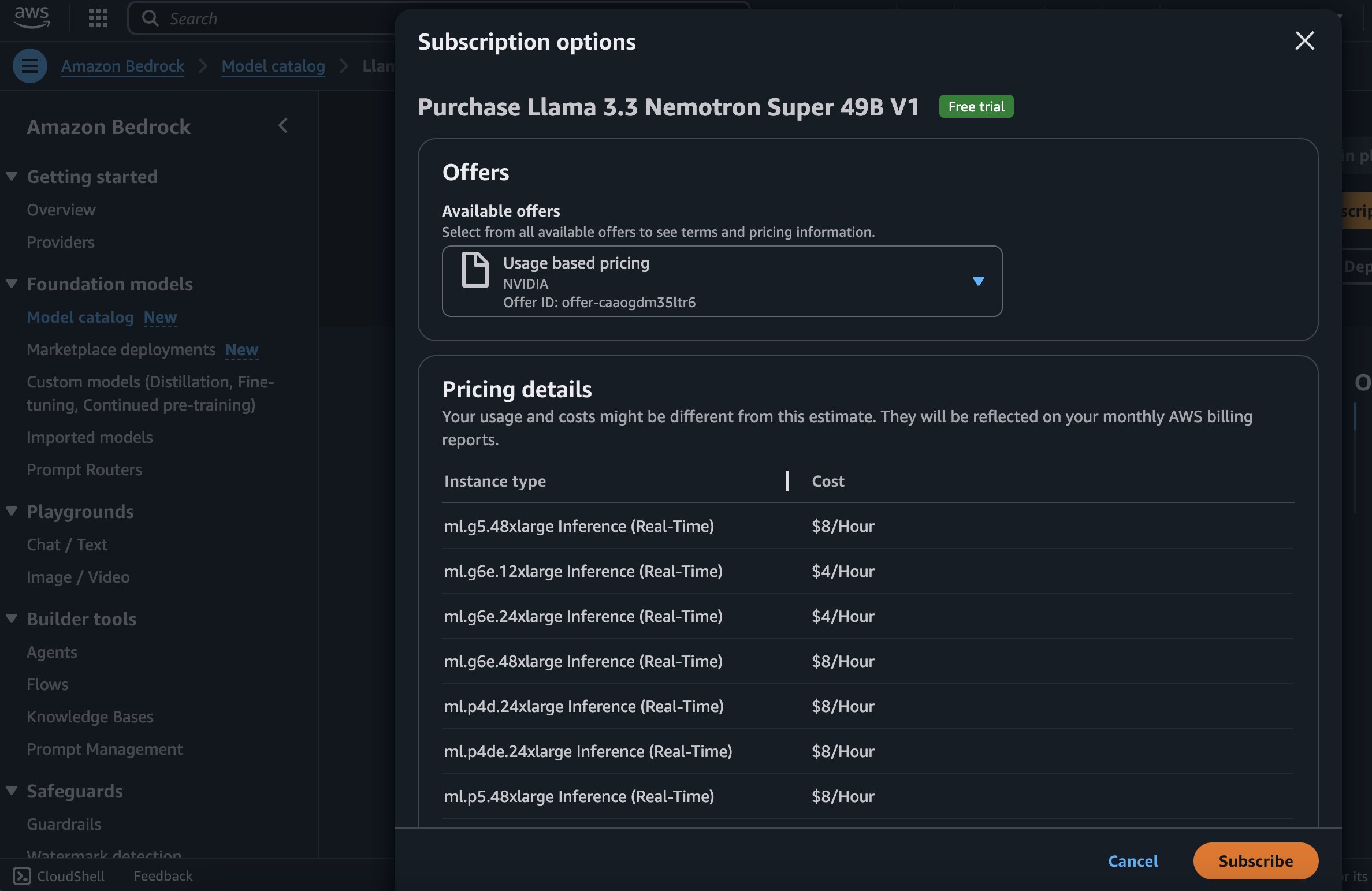
- On the model detail page, choose Deploy.
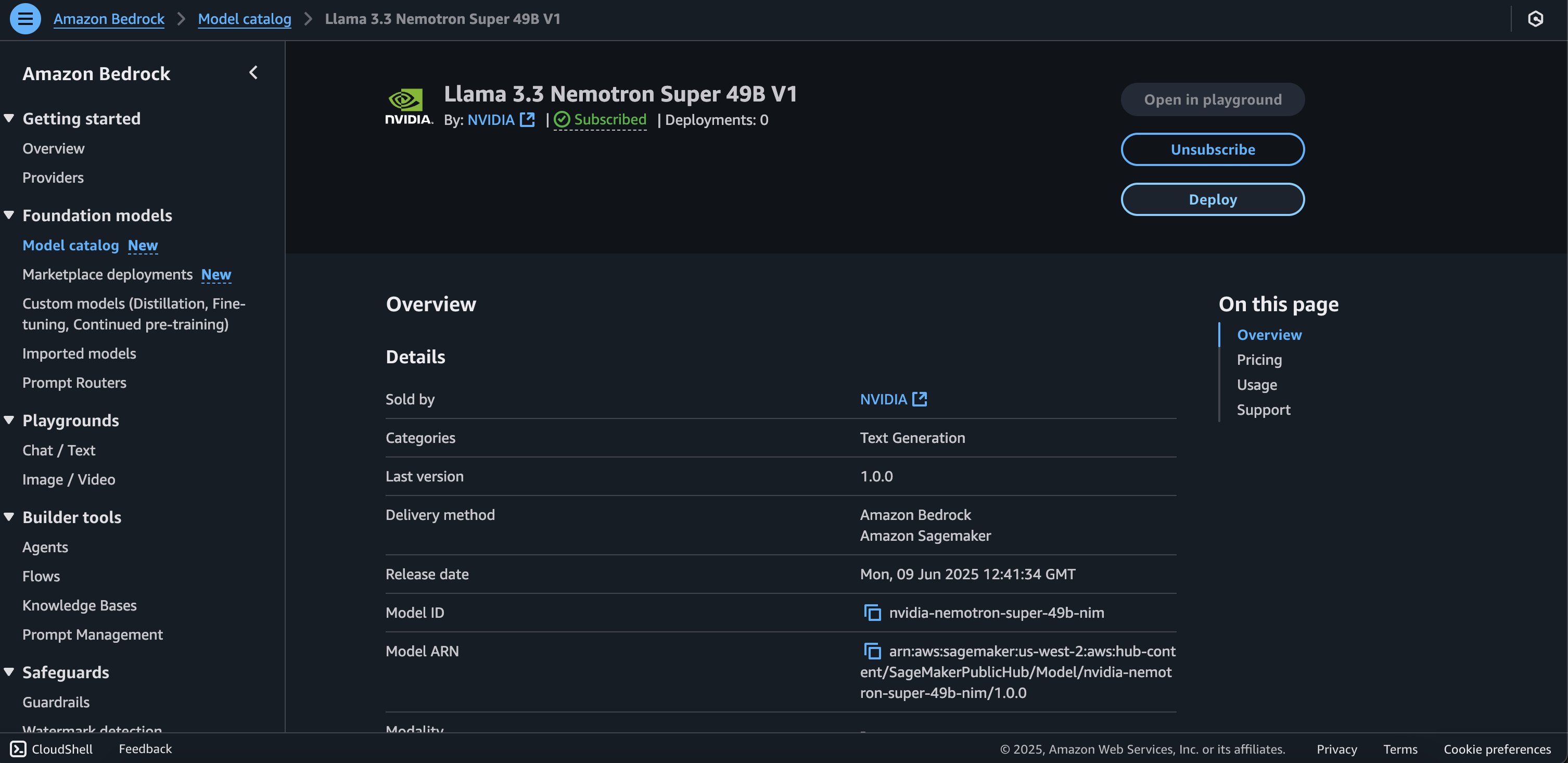
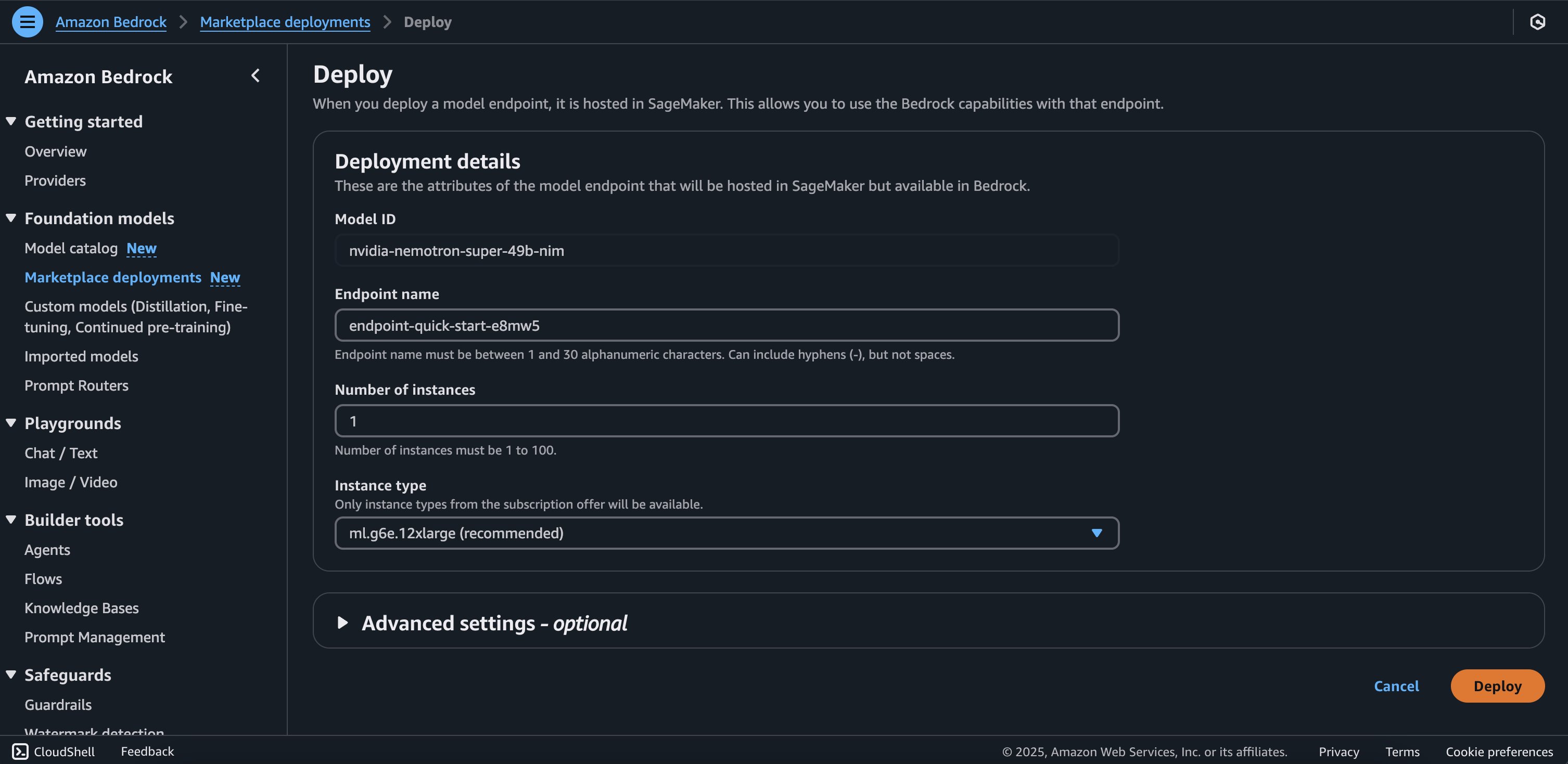
You will be prompted to configure the deployment details for the model. The model ID will be pre-populated.
- For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters).
- For Number of instances, enter a number of instances (between 1–100).
- For Instance type, choose your instance type. For optimal performance with Nemotron Super, a GPU-based instance type like
ml.g6e.12xlargeis recommended.
Optionally, you can configure advanced security and infrastructure settings, including virtual private cloud (VPC) networking, service role permissions, and encryption settings. For most use cases, the default settings will work well. However, for production deployments, you should review these settings to align with your organization’s security and compliance requirements. - Choose Deploy to begin using the model.
When the deployment is complete, you can test its capabilities directly in the Amazon Bedrock playground.This is an excellent way to explore the model’s reasoning and text generation abilities before integrating it into your applications. The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results. A similar process can be followed for deploying the Llama 3.1 Nemotron Nano 8B V1 model as well.
Run inference with the deployed Nemotron endpoint
The following code example demonstrates how to perform inference using a deployed model through Amazon Bedrock using the InvokeModel api. The script initializes the bedrock_runtime client, configures inference parameters, and sends a request to generate text based on a user prompt. With Nemotron Super and Nano models, we can use a soft switch to toggle reasoning on and off. In the content field, set detailed thinking on or detailed thinking off.
Request
Response body
Amazon SageMaker JumpStart overview
SageMaker JumpStart is a fully managed service that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks. You can now discover and deploy Llama 3.3 Nemotron Super 49B V1 and Llama-3.1-Nemotron-Nano-8B-v1 in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, so you can derive model performance and MLOps controls with Amazon SageMaker AI features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in a secure AWS environment and in your VPC, helping to support data security for enterprise security needs.
Prerequisites
Before getting started with deployment, make sure your AWS Identity and Access Management (IAM) service role for Amazon SageMaker has the AmazonSageMakerFullAccess permission policy attached. To deploy the NVIDIA Llama Nemotron models successfully, confirm one of the following:
- Make sure your IAM role has the following permissions and you have the authority to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- If your account is already subscribed to the model, you can skip to the Deploy section below. Otherwise, please start by subscribing to the model package and then move to the Deploy section.
Subscribe to the model package
To subscribe to the model package, complete the following steps:
- Open the model package listing page and choose Llama 3.3 Nemotron Super 49B V1 or Llama 3.1 Nemotron Nano 8B V1.
- On the AWS Marketplace listing, choose Continue to subscribe.
- On the Subscribe to this software page, review and choose Accept Offer if you and your organization agree with EULA, pricing, and support terms.
- Choose Continue to with the configuration and then choose an AWS Region where you have the service quota for the desired instance type.
A product ARN will be displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
(Option-1) Deploy NVIDIA Llama Nemotron Super and Nano models on SageMaker JumpStart
For those new to SageMaker Jumpstart, we will go to SageMaker Studio to access models on SageMaker Jumpstart. The Llama 3.3 Nemotron Super 49B V1and Llama 3.1 Nemotron Nano 8B V1 models are available on SageMaker Jumpstart. Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.
Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK. 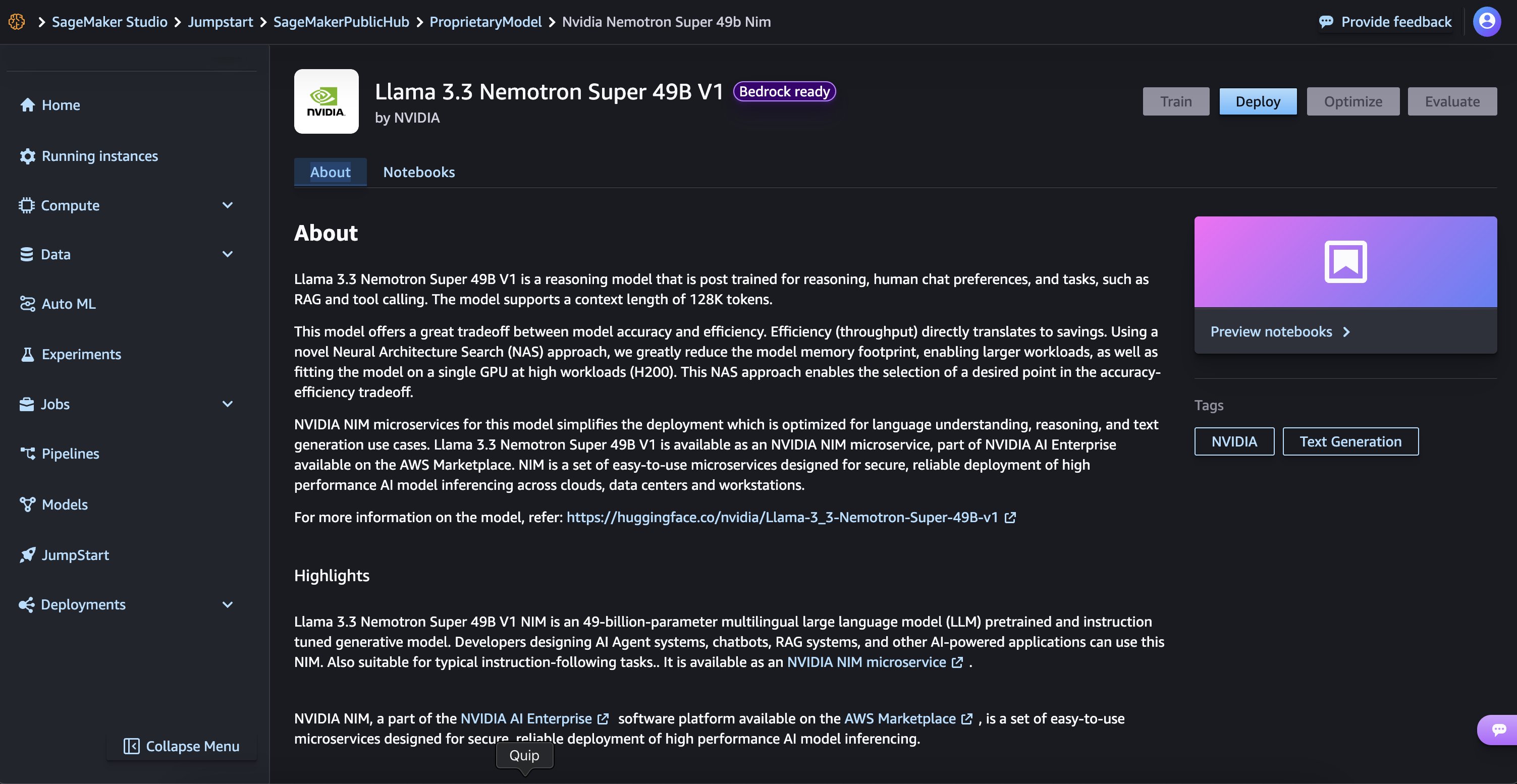
(Option-2) Deploy NVIDIA Llama Nemotron using the SageMaker SDK
In this section we will walk through deploying the Llama 3.3 Nemotron Super 49B V1 model through the SageMaker SDK. A similar process can be followed for deploying the Llama 3.1 Nemotron Nano 8B V1 model as well.
Define the SageMaker model using the Model Package ARN
To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
Create the endpoint configuration
Next, we can create endpoint configuration by specifying instance type, in this case it’s ml.g6e.12xlarge. Make sure you have the account-level service limit for using ml.g6e.12xlarge for endpoint usage as one or more instances. NVIDIA also provides a list of supported instance types that supports deployment. Refer to the AWS Marketplace listing for both of these models to see supported instance types. To request a service quota increase, see AWS service quotas.
Create the endpoint
Using the previous endpoint configuration we create a new SageMaker endpoint and add a wait and loop as shown below until the deployment finishes. This typically takes around 5-10 minutes. The status will change to InService once the deployment is successful.
Deploy the endpoint
Let’s now deploy and track the status of the endpoint.
Run Inference with Llama 3.3 Nemotron Super 49B V1
Once we have the model, we can use a sample text to do an inference request. NIM on SageMaker supports the OpenAI API inference protocol inference request format. For explanation of supported parameters please see Creates a model in the NVIDIA documentation.
Real-Time inference example
The following code examples illustrate how to perform real-time inference using the Llama 3.3 Nemotron Super 49B V1 model in non-reasoning and reasoning mode.
Non-reasoning mode
Perform real-time inference in non-reasoning mode:
Reasoning mode
Perform real-time inference in reasoning mode:
Streaming inference
NIM on SageMaker also supports streaming inference and you can enable that by setting stream as True in the payload and by using the invoke_endpoint_with_response_stream method.
Streaming inference:
We can use some post-processing code for the streaming output that reads the byte-chunks coming from the endpoint, pieces them into full JSON messages, extracts any new text the model produced, and immediately prints that text to output.
Clean up
To avoid unwanted charges, complete the steps in this section to clean up your resources.
Delete the Amazon Bedrock Marketplace deployment
If you deployed the model using Amazon Bedrock Marketplace, complete the following steps:
- On the Amazon Bedrock console, in the navigation pane in the Foundation models section, choose Marketplace deployments.
- In the Managed deployments section, locate the endpoint you want to delete.
- Select the endpoint, and on the Actions menu, choose Delete.
- Verify the endpoint details to make sure you’re deleting the correct deployment:
- Endpoint name
- Model name
- Endpoint status
- Choose Delete to delete the endpoint.
- In the Delete endpoint confirmation dialog, review the warning message, enter
confirm, and choose Delete to permanently remove the endpoint.
Delete the SageMaker JumpStart Endpoint
The SageMaker JumpStart model you deployed will incur costs if you leave it running. Use the following code to delete the endpoint if you want to stop incurring charges. For more details, see Delete Endpoints and Resources.
Conclusion
NVIDIA’s Nemotron Llama3 models deliver optimized AI reasoning capabilities and are now available on AWS through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. The Llama 3.3 Nemotron Super 49B V1, derived from Meta’s 70B model, uses Neural Architecture Search (NAS) to achieve a reduced 49B parameter count while maintaining high accuracy, enabling deployment on a single H200 GPU despite its sophisticated capabilities. Meanwhile, the compact Llama 3.1 Nemotron Nano 8B V1 fits on a single fits on a single H100 or A100 GPU (P5 or P4 instances) while improving on Meta’s reference model accuracy, making it ideal for efficiency-conscious applications. Both models support extensive 128K token context windows and are post-trained for enhanced reasoning, RAG capabilities, and tool calling, offering organizations flexible options to balance performance and computational requirements for enterprise AI applications.
With this launch, organizations can now leverage the advanced reasoning capabilities of these models while benefiting from the scalable infrastructure of AWS. Through either the intuitive UI or just a few lines of code, you can quickly deploy these powerful language models to transform your AI applications with minimal effort. These complementary platforms provide straightforward access to NVIDIA’s robust technologies, allowing teams to immediately begin exploring and implementing sophisticated reasoning capabilities in their enterprise solutions.
About the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
 Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
 Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
 Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace.
 Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
 Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
 Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.